Data Lakehouse, Data Fabric, and Data Mesh are hot topics in the Data Platform community. Let’s discuss these topics in detail as part of the Demystifying Metadata Management series.
If you are visiting this series first time then the recommendation is to complete Demystifying Metadata Management Part 1 of the series to have basic knowledge of the metadata components.
In this part, we will discuss the following topics:
- Data Lake-House
- Data Fabric
- Data Warehouse vs Data Lake vs Data Fabric
- Data Virtualization
- Data Mesh
- Data Mesh vs Data Mart vs Data Fabric
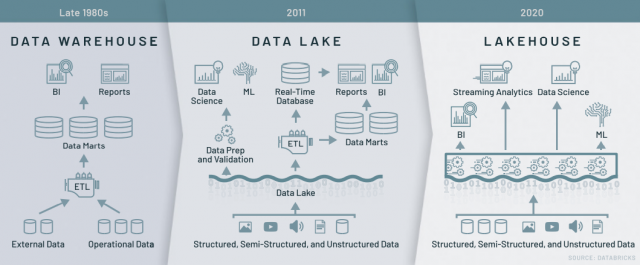
Data LakeHouse:
Do not worry, if you haven’t heard this word before. It’s the combination of Data Warehouse and Data Lake. Businesses can leverage cost-effective storage of data lake and analytics-optimized features of the data warehouse. The Organizations will eventually ETL certain portions to the data lake and subsequently some portion of data to the warehouse to make it a two-tier architecture.
Data Lakehouse is a step towards making it a single-tier architecture, that can benefit:
- Businesses don’t have to worry about fragile engineering ETLs to transfer data among multiple data stores.
- Reduced Data Redundancy by enabling a single repository for all data.
- Reduced cost by streamlining ETL and single-tier architecture.
- Increased agility and up-to-date data enable quick analytics and reports on near real-time data.
- Able to combine transaction, ACID, and structured data features of warehouse and quick and easy data access into a single solution.
Data Lake could enable quick access to data, but data warehouse provides lower latency and better performance of SQL queries.
Lake House Solutions are:
- Delta Lake
- Apache Hudi
- Apache Iceberg
Good read on Data Lakehouse: Blog by Splunk
Data Fabric:
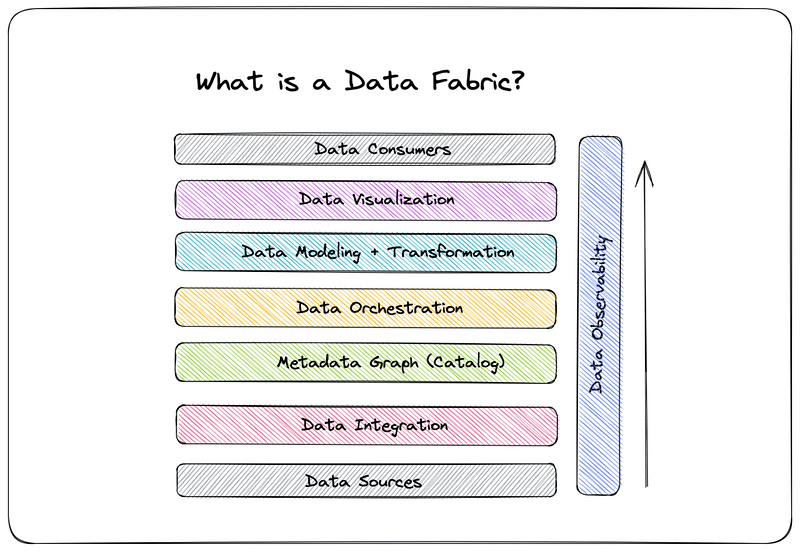
Data Fabric is a collection of practices and tools(Software or Hardware) used to implement data connectivity across the entire company estate — on-premises systems, all cloud data storage services, hybrid storage systems, and even edge devices. Think of a data fabric solution as the nervous system in our bodies. Its purpose is to distribute various kinds of information to the organs (business systems), requiring it for decision-making.
Data fabric can also be referred to as an architecture that facilitates end-to-end data pipelines, systems, and databases.
Historically, an enterprise may have had different ERP, CRM, supply chain, or customer data platforms, which persist data in different and separate environments. There is a high chance that these systems will have a potential overlap of data. Decision-making requires data across multiple places to understand the in-depth behavior of customer’s lifecycle and future predictions and thus there is a requirement to create a system that could have access to the data from across data stores. Data fabric helps to build such a system.
Thus, Data Fabric allows more holistic and data-centric decision-making by applying sophisticated automation and tooling. There is no single tool or platform to fully set up data fabric architecture. A mix of solution, management, and monitoring will be required to create a Data Fabric Solution.
To establish a Data Fabric, there is no set of rules or practices. The sophistication of Data Fabric Architecture is based on the use case and the organization’s needs. Data Fabric implementation could be costly if not procured with precaution and need.
Data Virtualization must not be confused with Data Fabric. Data Virtualization is one of the technologies to enable Data Fabric. We will discuss more about Data Virtualization in the later part of this blog.
Data fabric is a complementary “coating” you can use to connect disparate data lake solutions with data warehouse tools to resolve interoperability issues, improve data distribution speed, and achieve better data standardization.
Data Fabric Solutions:
- SAP Data Intelligence
- IBM Data Fabric
- Google Cloud Dataplex
Good Read on Data Fabric: A blog by Infopulse
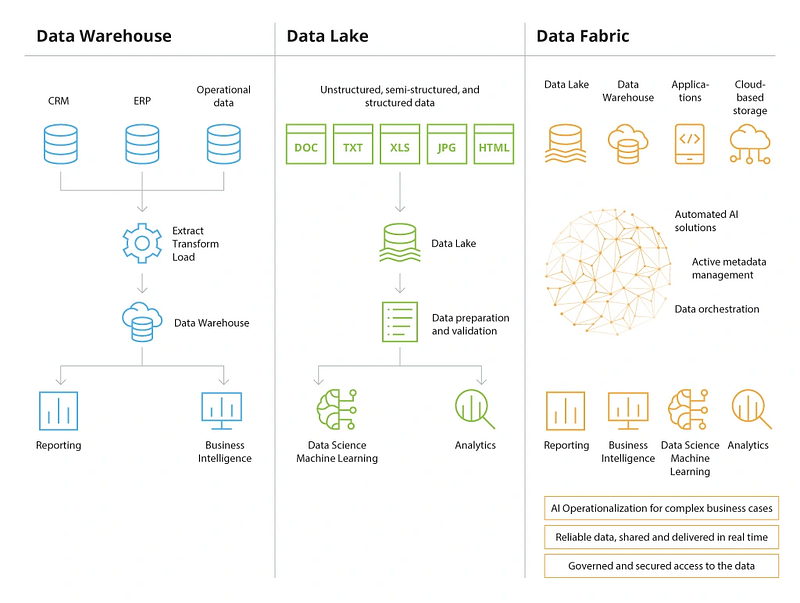
Data Warehouse vs Data Lake vs Data Fabric:
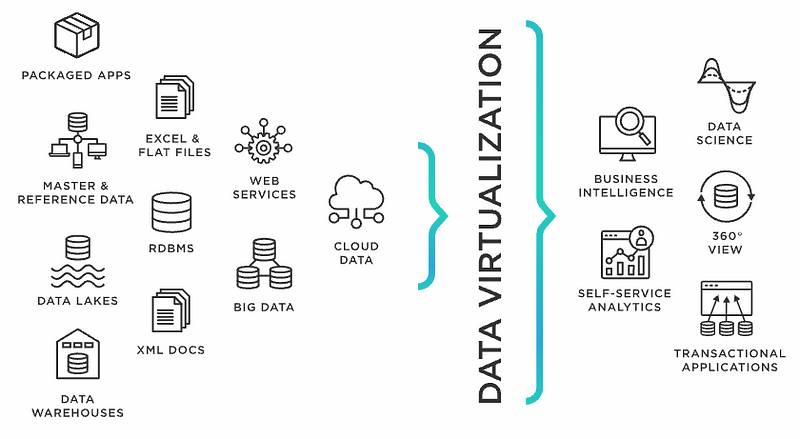
Data Virtualization:
Rather than moving data physically using any ETL process. Data Virtualization is a process or architecture to create a metadata layer above physical data to create a virtual data layer. This allows users to leverage the source data in real time.
Data virtualization can also be extended to add an extra security layer to enable row-level or column-level security.
Good Read on Data Virtualization: A blog by tibco
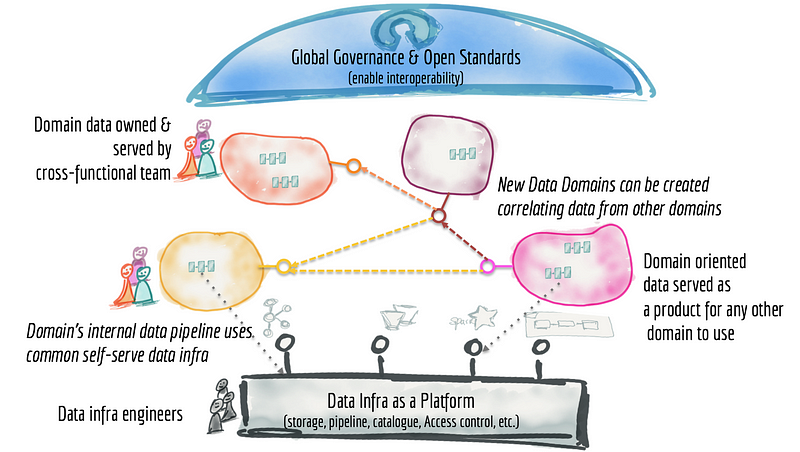
Data Mesh:
“Data Mesh” – The term coined by Zhamak Dehghani in her 2019 blog is a “socio-technical paradigm”. It is a process or shift in organizational culture to replace centrally managed data lakes or warehouses with independent lakes or warehouses. Each independent warehouse is to be managed by business or domain owners. Each domain owner is responsible for their ETL to get data to their domain-based warehouse. Thus, in Data Mesh, Ownership, responsibility, and accountability of management for ETL, monitoring, and management of centralized warehouse/data lake gets distributed among multiple small and less complex domain-based warehouses.
Data Marts must not be confused with Data Mesh. Data Marts are dependent upon the central warehouse to provide data. On the contrary, Data Mesh architecture is to replace central warehouse.
Read more about the difference between Data Mesh and Data Marts here.
Good Read on Data Mesh: A blog by upsolver
Data Fabric Vs Data Mesh:
A data fabric and a data mesh both provide an architecture to access data across multiple technologies and platforms, but a data fabric is technology-centric, while a data mesh focuses on organizational change. as per Serra in a June blog post:
Data mesh is more about people and process than architecture, while a data fabric is an architectural approach that tackles the complexity of data and metadata in a smart way that works well together.
Good read on Data Mesh vs Data Fabric: A blog by analyticsindiamag
[Writer’s Corner]
While writing the Demystifying Metadata Management series, I had an opportunity to talk to a few brightest minds in the industry. In the past few years, organizations have been successful in establishing central Data Warehouses. This central data warehouse is responsible for producing data Data Marts, which in turn is responsible for analytics or multiple domains. There are two major challenges with this architecture:
- To keep the data in sync across all the Data Marts.
- Complex central ETL and monitoring of complex architecture.
Data Fabric and Data Mesh are paradigm shifts that organizations are trying to adapt to overcome this problem.