
What is a Name-Matching Problem?
Identifying similar people, objects, or entities across multiple interfaces to create a correlation in order to draw the patterns is called a Name-Matching Problem.
Name-Matching Problem in detail:
Data is the new Oil, Analytics is the Refinery and Intelligence is the Gasoline which drives the Growth.
Tiffani Bova
Simple yet very preeminent quotation. If you look closely at the above quotation you will find absolutely each organization in the world independent of their size or location working only to achieve this goal. Now if you look more in-depth, you will find this is made up of 3 entities DATA, ANALYTICS, and INTELLIGENCE.
There is no Growth without Intelligence and there is no intelligence without analytics and there is no Analytics without Data.

Now we know Data is the basic need for any organization and the Internet is the most common source of data. Now deep dive into the name-matching problem.
The Internet is overloaded with data, and there are numerous ways an organization can get data from multiple entities. Data is nothing but a resource for an organization but data without proper identification (Consistency and Integrity) will very soon turn into a liability if not nurtured properly. Here Nurturing is nothing but combining this data with the right demographics(Person Names, ages, contacts, etc.). If an Organization has data without proper consistency then it might show wrong metrics which can lead the organization to bad decisions. Therefore name matching is important to identify a person’s behavior daily, weekly, or occasionally.
Example of Name-Matching Problem:
For Example, A person looks for shoes from 8-9PM every 150 days using social media advertisements with the exception that he also shops for shoes around 10-15 days before Christmas using multiple search engines and e-commerce websites. This information can be used to target the right set of customers at the right time.
If an Organization fails to identify the same person on multiple browsers or multiple social media or e-commerce platforms then they might lose out on some sales and capital on digital marketing.

A lot of organizations are involved in mining demographic information from across applications like e-mail, customer or patient records, news articles, and business or political memorandums that they might have received.
Sources of Names or Texts variation:
By Now we have an understanding of:
- Why Data is Important for an Organization?
- What is the name-matching problem and Why this is important for an Organization?
Hence, we will move next phase to understand where is the origin of this problem. Is there a way to identify the source so we can apply our algorithm on the basis of the source?
For Example, If Data comes from a third-party application form where the limitation of name length is 20 letters then all the names which are of 20 words might be looked for abbreviation or as pruned data and can be handled accordingly and will not go for other costly algorithms. These few techniques could definitely save a significant amount of time and dollars.
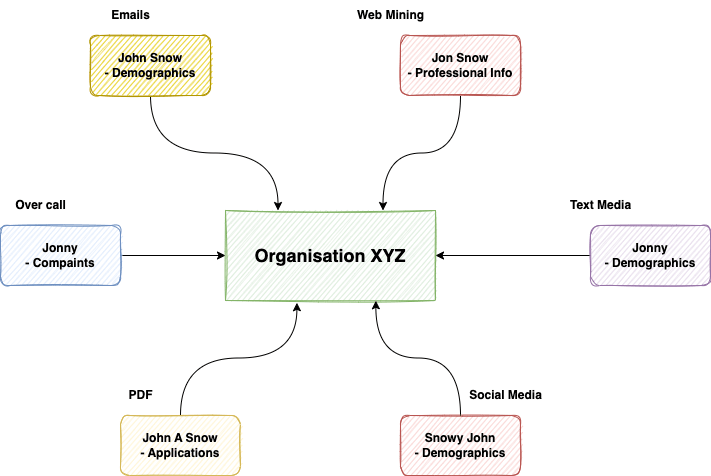
These are a few examples that will you identify the cases for your organization and will help you apply the right algorithm for the right problem.
- Handwritten OCR:
q and gorm and rncan be misrepresented as similar. - Manual Keyboard Data Entry or Over Phone: Neighbouring keyboard keys like
n and more and r. - Limitation of maximum length allowed: Input field forces people to use abbreviations or initials only.
- Deliberately provide a modified name: Faith on the organization or to avoid public data.
- Different Demographics: The person entering data does not know the right format for other demographics. Someone sitting in the US can put the wrong spelling for Indian or Spanish names or vice-versa.
These are basic examples where an entity(End-user or Data entry professional) can create multiple variations of names for the same organization or data retrieved from multiple organizations.
Type and Examples of different Referential/Demographic data:
Let’s take a few more examples where spelling mistakes or phonetic name variations could occur.
One of the most important parts of making analytics score better is to standardize referential data* which includes names and addresses. If we look only into the above-mentioned problem then we can divide the matching problem into two categories.
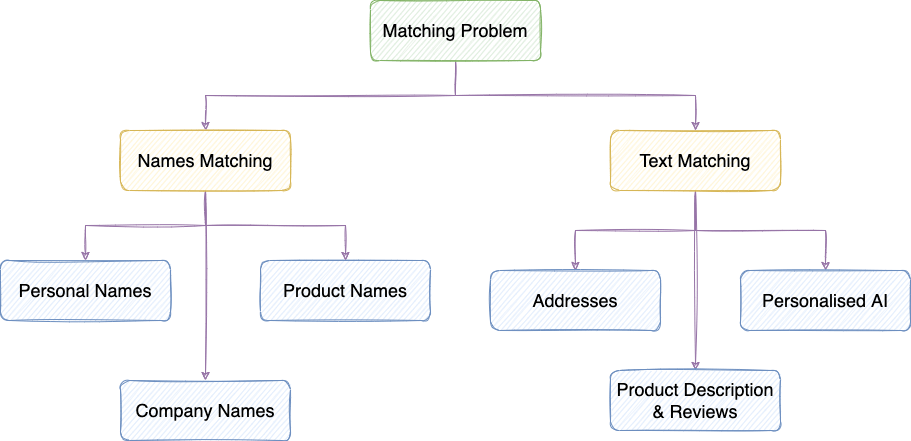
Name Matching
- Personal Name Matching: While there is only one correct spelling for many words, there are often several valid spelling variations for personal names. Examples:
- NickName like
'Bill' rather than 'William' - Phonetically Similar like
'Gail', 'Gale' and 'Gayle' - Personal names sometimes change over time, After marriage or religion change.
- NickName like
- Company Names Matching:
- Abbreviations like
LTD, Ltd, LimitedorCorp, CorporationorIBM and International Business Machinecan be used interchangeably across documents. - Typographical Errors like
Oracle and Orcle - Omissions like
Goyal & Sons and Goyals
- Abbreviations like
- Product Name Matching:
- Canon PowerShot a20IS”, “NEW powershot A20 IS from Canon” and “Digital Camera Canon PS A20IS” should all match “Canon PowerShot A20 IS”
Text Matching:
- Address Matching:
- 134 Ashewood Walk, Summerhill Lane, Portlaoise
- 134 Summerhill Ln, Ashewood Walk, Summerhill, Portlaoise, Co. Laois, R32 C52X, Ireland
- Product review and NLP fuzzy matching: Product reviews can be confusing due to very similar product names or review text does not have a very clear picture. Example:
- I still think the Lenovo T400 is better than Lenovo R400. Though T400 has its own drawbacks
- Personalized AI learning: Chat Messages could sometimes be confusing to get a sense of it. Example:
- John Snow: What’s so fuzzy about this?
- Danny: I think it was a good fuzz.
Similarly, there could be multiple other such examples where name or text matching can create huge differences, and collating all that information is very crucial.
Why is Name-Matching so hard?
By Now we have an understanding of
- Why Data is Important for an Organization!
- What is the name-matching problem and Why this is important for an Organization!
- Sources and examples of multiple name variations
Now, let’s understand, why name matching is so hard and most companies are still not able to figure out the solution with a 100% match score.
- Names are heavily influenced by people’s cultural backgrounds and first name, middle name, and last name can be represented in different ways.
- Names are often recorded with different spellings, and applying exact matching leads to poor results. The most common cases that I can come up with are:
- Spelling Errors(80%)
- Spelling Variation: ‘O’Connor’, ‘OConnor’ and ‘O Connor’
- Phonetical Similarity: Gail & Galye
- Tina Smith might be recorded as ‘Christine J. Smith’ and as ‘C.J.Smith-Miller’
- Short forms: Like ‘BOB for Robert, or ‘Liz’ for Elizabeth
- Some European countries favor compound. ‘Hans-Peter’ or ‘Jean-Pierre’
- Hispanic and Arabic names can contain more than two surnames.
- Record Linkage, where the record contains more than just names
- There is computational complexity when matched with a large volume of data.
These examples show why the name-matching problem is so hard, though there are multiple ways to resolve the issues. Let’s discuss those techniques in detail.
Name Matching Techniques
By now, we understand the source of different names and their complexities. To improve the matching accuracy, many different techniques for approximate name matching have been developed in the last four decades and new techniques are still being invented. Most of the solutions are based on the pattern, phonetic, or a combination of these two approaches.
In this document, we will discuss each approach on a very high level, but I will add more blogs to detail each technique in detail.
Phonetic Encoding:
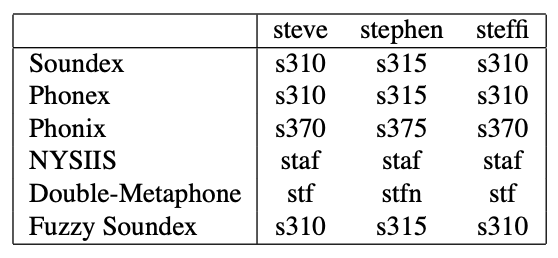
1. Soundex: It keeps the first letter in a string and converts the rest into numbers using below mapping/encoding table below.
For example
- perter is p360
- christen is c623

2. Phonex: It is a variation of Soundex that tries to improve the encoding quality by pre-processing names according to their English pronunciation before the encoding
3. Phonix: This encoding goes a step further than phonex and applies more than one hundred transformation rules on groups of letters before encoding on the basis of below encoding table below. This algorithm is slow comparatively due to a large number of transformations.

4. NYSIIS: (The New York State Identification Intelligence System) It is based on transformation rules similar to Phonex and Phonix, but it returns a code that is only made of letters.
5. Double Metaphone: Specialized in European and Asian names. For example ‘kuczewski’ will be encoded as ‘ssk’ and ‘xfsk’, accounting for different spelling variations.
6. Fuzzy Soundex: It is based on q-gram substitution. The fuzzy Soundex technique is combined with a q-gram-based pattern-matching algorithm, and accuracy results better than Soundex.
The below table shows how different algorithms will create encoding for the same word.
Pattern Matching:
Levenstein or Edit Distance:
The smallest number of edit operations (insertions, deletions, and substitutions) required to change one string into another.
Damerau-Levenstein Distance:
Measuring the difference between two sequences. It is a variant of the Levenshtein distance, with the addition of a provision for the transposition of two adjacent characters. The Damerau-Levenshtein distance between two strings is the minimum number of operations (consisting of insertions, deletions, substitutions, and transpositions of two adjacent characters) required to transform one string into the other.
Bag Distance:
The bag distance algorithm compares two sets of items, and calculates the distance between them as the number of items that are present in one set but not the other. It is a simple and fast algorithm, but it does not take into account the order or frequency of the items in the sets.
Smith-Waterman:
Smitth-Waterman is a dynamic programming algorithm used for local sequence alignment. It is used to align two sequences in a way that maximizes the number of matching characters while allowing for the insertion of gaps to optimize the alignment. It was originally developed to find optimal alignments between biological sequences, like DNA or proteins.
Longest common sub-string (LCS):
The longest common substring (LCS) is a string that is common to two or more strings and is the longest string that is a substring of all the strings. It is used to find the similarities between two or more strings and is often used in text comparison, data mining, and natural language processing. There are various algorithms for finding the LCS, including dynamic programming and suffix trees.
Q-grams:
The Q-gram algorithm is a method for comparing strings by breaking them down into fixed-length substrings, or “grams”, and comparing the set of grams for each string. It is a fast and simple algorithm, but it can be less accurate than other methods, as it does not take into account the order of the grams or the distances between them. Q-grams are often used in spelling correction, text search, and information retrieval.
Positional Q-grams:
Positional Q-grams is a variant of the Q-gram algorithm that takes into account the position of the grams within the string. It is used for comparing strings by breaking them down into fixed-length substrings and comparing the set of grams for each string, while also considering the positions of the grams in the original string. Positional Q-grams can be more accurate than regular Q-grams, as it takes into account the order of the grams within the string. It is often used in information retrieval and natural language processing.
Skip-grams:
The skip-grams algorithm was developed as an experiment on multi-lingual texts from different European languages showing improved results compared to bigrams, trigrams, edit distance, and the longest common sub-string technique.
Compression:
Compression matching is a method for comparing strings by comparing their compressed representations. The idea is that strings that are similar will compress to a smaller size than strings that are dissimilar. To perform compression matching, the strings are first compressed using a lossless compression algorithm, such as gzip or bzip2. The compressed representations of the strings are then compared using a string distance metric, such as the Levenshtein distance or the Jaccard coefficient. Compression matching can be an effective way to compare strings, especially for large strings or datasets. However, it can be computationally expensive, as it requires the strings to be compressed and decompressed.
Jaro:
The Jaro algorithm is commonly used for name matching in data linkage systems. It accounts for insertions, deletions, and transpositions. The algorithm calculates the number c of common characters (agreeing characters that are within half the length of the longer string) and the number of transpositions.
Winkler:
The Winkler algorithm improves upon the Jaro algorithm by applying ideas based on empirical studies which found that fewer errors typically occur at the beginning of names. The Winkler algorithm therefore increases the Jaro similarity measure for agreeing initial characters (up to four).
Sorted-Winkler:
If a string contains more than one word (i.e. it contains at least one whitespace or other separator), then the words are first sorted alphabetically before the Winkler technique is applied (to the full strings). The idea is that (unless there are errors in the first few letters of a word) sorting of swapped words will bring them into the same order, thereby improving the matching quality.
Permuted-Winkler:
In this more complex approach, Winkler comparisons are performed over all possible permutations of words, and the maximum of all calculated similarity values is returned.
Combined Techniques:
Editex:
Aim at improving phonetic matching accuracy by combining edit distance-based methods with the letter-grouping techniques of Soundex and Phonix. The edit costs in Editex are 0 if two letters are the same, 1 if they are in the same letter group, and 2 otherwise. Editex performed better than edit distance, q-grams, Phonix, and Soundex on a large database containing around 30,000 surnames.
Syllable alignment distance:
This recently developed technique, called Syllable Alignment Pattern Searching (SAPS) [13] is based on the idea of matching two names syllable by syllable, rather than character by character. It uses the Phonix transformation (without the final numerical encoding phase) as a preprocessing step, and then applies a set of rules to find the beginning of syllables. An edit distance-based approach is used to find the distance between two strings.
Problem with Current Name Matching Techniques?
We have discussed the characteristics of personal names and the potential sources of variations and errors in them, and we presented an overview of both pattern-matching and phonetical encoding-based name-matching techniques. Experimental results on different real data sets have shown that there is no single best technique available. The characteristics of the name data to be matched, as well as computational requirements, have to be considered when selecting a name-matching technique.
Personal name matching is very challenging, and more research into the characteristics of both name data and matching techniques has to be conducted in order to better understand. A more detailed analysis of the types and distributions of errors is needed to better understand how certain types of errors influence the performance of matching techniques.
How Python or Databases can help in Name-Matching?
Python also has a lot of phenomenal libraries created by a lot of good developers. A few libraries are worth looking for:
- The Fuzz
- hnmi
- Fuzzy-wuzzy
- Namematcher
- dedupe
- TF-IDF Vectorizer scikit-learn
Not only Python but other languages also have similar libraries which can provide in-built functionality and which can save a few lines of complex code.
Some databases also provide some in-built matching functionalities which can definitely save some network bandwidth in your production system.
- Jaro-Winkler by Snowflake
- Jaccard Index by Snowflake
- Edit Distance by Snowflake
- Levenstein by Postgres
- Trigrams by Postgres
- AWS + Azure in-built Machine Learning
Conclusion
I hope you have learned something new today and please stay tuned for more such blogs. In the near future, I plan to add more detailed documentation for each of the algorithms to discuss each of their use cases. Metadata Management plays a crucial role in managing such large systems where data is coming from huge number of sources. Read more about Metadata Management here.
References and Courtesy:
- The Australian National University(TR-CS-06-02) by Peter Christen
- https://undraw.co/