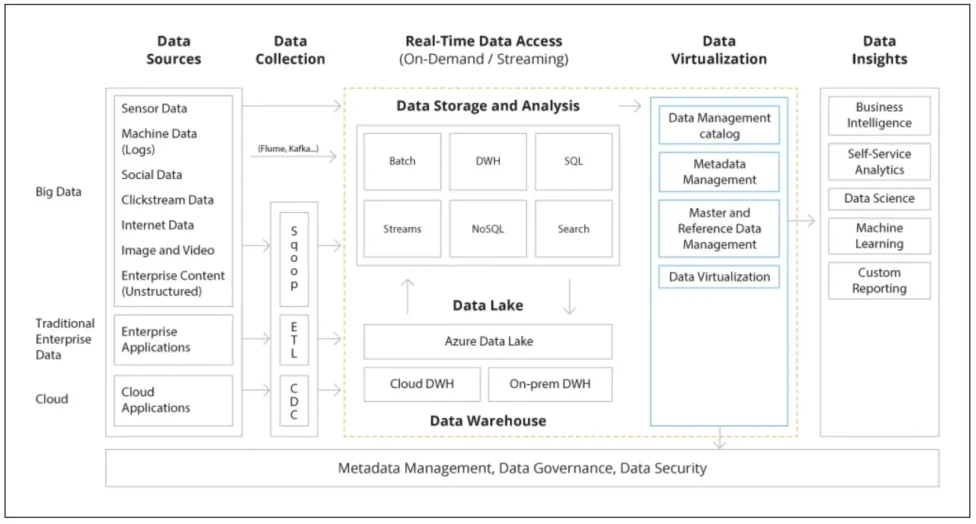
Metadata Management provides a base for an organization’s Data Platform Architecture.
In this part, we will discuss the following topics in regard to Metadata Management:
- Data
- Metadata
- Data Democratization
- Data Literacy
- Data Designations: Data Architect, Data Engineer, Data Steward, Data Analyst & Data Scientist
- Data Warehouse, Data Lake, and Data Mart.
Check out the complete series on Metadata Management and its components.
What is Data?
Data is a collection of raw and unorganized facts that can be used in calculating, reasoning, or planning. Without proper processing and organizing, it is useless. That’s where metadata comes into play.
Good read on Data: Blog by Dataedo

What is Metadata?
In plain English, Metadata is data about data. To clarify more, it is a description and context that helps to organize, find, and understand data, using information such as format, origin, creation date, modification date, etc.
Data stores information, but if you don’t know how to interpret it, you don’t have access to this information. Metadata enables you to understand and extract the information.
Metadata, you see, is really a love note — it might be to yourself, but in fact it’s a love note to the person after you, or the machine after you, where you’ve saved someone that amount of time to find something by telling them what this thing is.
Cit. Jason Scott’s Weblog

Good read on metadata: Blog by Dataedo
What is Data Democratization?
Empowering employees and stakeholders of an organization with the right set of tools that enables them to make informed decisions.
Data democratization is the ongoing process of enabling everybody in an organization, irrespective of their technical knowledge — how, to work with data comfortably, to feel confident talking about it, and as a result, to make data-informed decisions and build customer experiences powered by data.
Data Democratization have answers to questions like:
“Experts in my company are too busy to help me”.
“I do not have access to data”
“I can not trust the data”.
Data democratization is an ongoing process and needs a cultural shift because it depends on an ongoing process called Data Literacy.

Good read on Data Democratization: Blog by Towards datascience
What is Data Literacy?
The ability to read, analyze, work, and communicate with data is known as data literacy — it is now so critical to companies that it has been hailed as the second language of business by Gartner. The global pandemic highlighted its importance, with many companies starting to rely on data to detect new patterns, respond to changing customer behavior, and make first-of-a-kind decisions in a new environment of many unknown factors.
Poor data literacy is ranked as the second-biggest internal roadblock to the success of the CDO’s office, according to the Gartner Annual Chief Data Officer Survey.
In upcoming years, data literacy will become essential in driving business value, demonstrated by its formal inclusion in over 80% of data and analytics strategies and change management programs.
One common misconception about Data Democratization and Literacy is that now everyone in the company will know everything related to the data and get you details about data in no time and there will be no need for a Subject Matter Expert or Data Architect – This is not true.
Data Literacy and Democratization provide ways to be independent and able to complete tasks and take the company in the right direction and have no place for presumption.
Good read on Data Literacy: Blog by thedataliteracyproject

Data Architect & Data Engineer:
The data architect and data engineer titles are closely related and, as such, frequently confused. The difference in both roles lies in their primary responsibilities:
- Data Architects design the vision and blueprint of the organization’s data framework, while the Data Engineer is responsible for creating that vision.
- Data Architects provide technical expertise and guide data teams in bringing business requirements to life; Data Engineers ensure data is readily available, secure, and accessible to stakeholders (data scientists, and data analysts) when they need it.
- Data Architects have substantial experience in data modeling, data integration, and data design and are often experienced in other data roles; data engineers have a strong foundation in programming with software engineering experience.
- The Data Architect and the Data Engineer work together to build the organization’s data system.
Good Read on Data Architect vs Data Engineer: Blog by rsTask

Data Analyst, Data Scientist & Data Steward:
- Data Analysts gather data from various databases and warehouses, filter, and clean it. Data Scientists perform ad-hoc data mining and gather large sets of structured and unstructured data from several sources.
- Data Analysts write complex SQL queries and scripts to collect, store, manipulate, and retrieve data from RDBMS such as MS SQL Server, Oracle DB, and MySQL. Data Scientists use various statistical methods and data visualization techniques to design and evaluate advanced statistical models from vast volumes of data.
- Data Analysts create different reports with the help of charts and graphs using Excel and BI tools. Data Scientists build AI models using various algorithms and in-built libraries.
- Data Analysts spot trends and patterns in complex datasets. Data Scientists automate tedious tasks and generate insights using machine learning models.

Data Steward
At a high level, handle day-to-day operations on policies created by Data Architect.
The Data Steward is the “go-to” guy for everyone working with data within the company. Typical data steward roles and responsibilities can be grouped as:
- Operational Oversight — a Data Steward oversees the lifecycle of a data set. They are responsible for defining and implementing rules and regulations for the day-to-day operational and administrative management of data and systems.
- Data Quality — Data stewardship responsibilities include establishing data quality metrics and requirements, like setting acceptable values, ranges, and parameters for every data element.
- Privacy, Security, and Risk Management — data protection is a key aspect of Data Steward responsibilities. A steward must establish regulations and conventions that govern data proliferation to ensure that data privacy controls are exercised in all processes.
- Policies and Procedures — Data Steward, also establish policies and procedures for data access, including authorization criteria based on any individual and/or the role.
Good read on Data Steward vs Data Analyst: Blog by Simplilearn
Difference between Data Warehouse & Data Lake & Data Mart:
Data Warehouse(DW)
It is a system for aggregating data from connected databases — and then transforming and storing it in an analytics-ready state. The main benefits of a data warehouse are effective data consolidation, fast pre-processing, and easy self-access for business users. The key constraint of using a data warehouse solution is the need to pre-transform all data using standard schemas. This increases the usage costs and reduces scalability potential.
Data warehouse solutions:
- Azure Synapse Analytics
- Amazon Redshift
- Google BigQuery
- Snowflake

Data Lake:
It is a centralized cloud-based repository for storing raw (unprocessed, non-cataloged, or pre-cleansed) data from various systems. Unlike DWHs, data lake technology allows storing both structured and unstructured data of any size (such as object blobs or files). Cloud data lakes are also more scalable and support more querying methods for data retrieval and analysis — a factor data scientists well appreciate.
Data lake solutions:
- Azure Data Lake
- Amazon S3
- Apache Hadoop
Data Mart:
Data Mart is a more focused subset of data present in a Data Warehouse. It is generally concerned with a single team of departments like finance, marketing, or sales. It is smaller, more focused, and may contain summaries of data that best serve its community of users. A data mart might be a portion of a data warehouse, too.
Data Mart has a few benefits over giving access to the full warehouse to all the departments:
- Cost-efficiency
- Simplified data access
- Quicker access to insights
- Simpler data maintenance
- Easier and faster implementation
Good read on Data Warehouse vs DataLake: Blog by AWS
Conclusion:
This is the first part of a series on metadata management. This part will help in building conceptual blocks of metadata management.
Please stay tuned for more parts of the series where we will discuss metadata management in detail and will also take one example to create metadata management for an example organization.
Keep Learning: Continue learning to advance components of metadata management in Demystifying Metadata Management — Part 2.